您的位置: 网站首页> Pandas教程> 当前文章
pandas的多重索引index、columns、索引值、names属性及表结构
![]() 老董-我爱我家房产SEO2022-05-03199围观,146赞
老董-我爱我家房产SEO2022-05-03199围观,146赞
推荐:7种方式实现pandas创建多重索引。上篇文章通过从excel读取数据来生成多重索引的df,本节我们从头来认识下pandas的多层索引,对其有1个整体的概念。我们先通过index和columns参数来创建1个多层索引的df。
要创建多层索引就要给index和columns传入二维列表才可以。代码如下:
# -*- coding:UTF-8 -*-
import pandas as pd
df= pd.DataFrame([[100,200,300,400],[1000,2000,3000,4000]],
columns=[['baidu','baidu','google','google'],['pc','mo','pc','mo']],
index=[[2020,2020],['1月','2月']])
print(df)
print('-------------')
print(df.index)
print(type(df.index))
print('=============')
print(df.columns)
print(type(df.columns))
baidu google
pc mo pc mo
2020 1月 100 200 300 400
2月 1000 2000 3000 4000
-------------
MultiIndex([(2020, '1月'),
(2020, '2月')],
)
<class 'pandas.core.indexes.multi.MultiIndex'>
=============
MultiIndex([( 'baidu', 'pc'),
( 'baidu', 'mo'),
('google', 'pc'),
('google', 'mo')],
)
<class 'pandas.core.indexes.multi.MultiIndex'>
上述可知,多重索引的行索引和列索引都是MultiIndex类型,索引中的一个元素是元组而不是单层索引中的标量,我们可以通过values属性直接获取索引的值,可以通过get_level_values来获取单层索引的值。
# -*- coding:UTF-8 -*- import pandas as pd df= pd.DataFrame([[100,200,300,400],[1000,2000,3000,4000]], columns=[['baidu','baidu','google','google'],['pc','mo','pc','mo']], index=[[2020,2020],['1月','2月']]) print(df.index.values) print(df.columns.values)
[(2020, '1月') (2020, '2月')]
[('baidu', 'pc') ('baidu', 'mo') ('google', 'pc') ('google', 'mo')]
索引是有name属性的,而对于多层索引,他具备的是names属性。我们创建双重索引的df后,可以直接通过传入元组分别给index和column的names属性赋值!
# -*- coding:UTF-8 -*-
import pandas as pd
df= pd.DataFrame(
[[10,20,30,400],[40,50,60,70],[11,22,33,44],[55,66,77,88]],
columns=[['baidu','baidu','google','google'],['pc','mo','pc','mo']],
index=[[2020,2020,2021,2021],['1月','2月','1月','2月']])
print(df)
print('-----------------------')
df.index.names = ('年','月')
df.columns.names = ('渠道','端口')
print(df)
baidu google
pc mo pc mo
2020 1月 10 20 30 400
2月 40 50 60 70
2021 1月 11 22 33 44
2月 55 66 77 88
-----------------------
渠道 baidu google
端口 pc mo pc mo
年 月
2020 1月 10 20 30 400
2月 40 50 60 70
2021 1月 11 22 33 44
2月 55 66 77 88
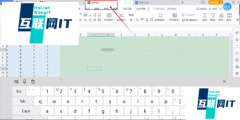
我们把这个完整的多层索引的df写入excel后,他的长相如下:
# -*- coding:UTF-8 -*-
import pandas as pd
df= pd.DataFrame(
[[10,20,30,400],[40,50,60,70],[11,22,33,44],[55,66,77,88]],
columns=[['baidu','baidu','google','google'],['pc','mo','pc','mo']],
index=[[2020,2020,2021,2021],['1月','2月','1月','2月']])
df.index.names = ('年','月')
df.columns.names = ('渠道','端口')
df.to_excel('test.xlsx')

很赞哦!
python编程网提示:转载请注明来源www.python66.com。
有宝贵意见可添加站长微信(底部),获取技术资料请到公众号(底部)。同行交流请加群

相关文章
文章评论
-
pandas的多重索引index、columns、索引值、names属性及表结构文章写得不错,值得赞赏